Data management
17
February 2026
Digitalisation, e facture, pilotage : l’Italie montre le futur du cabinet français
Digitalisation, e facture, pilotage : l’Italie montre le futur du cabinet français


L'Intelligence Artificielle est aujourd'hui perçue comme le levier de croissance ultime. Tout le monde veut son projet IA. Son chatbot. Son assistant intelligent. Son modèle prédictif. Pourtant, sans une base de données saine, l'IA se transforme rapidement en gouffre financier.
En janvier 2024, Sophie, CEO d'une entreprise e-commerce de 60 personnes, a investi 100 000 euros dans un projet ambitieux : automatiser son support client et prédire le churn, le taux d'attrition. Six mois plus tard, le projet est abandonné. L'IA générait des prédictions erronées et des réponses incohérentes. Le coupable ? Des données fragmentées et obsolètes. Ce n'est pas l'algorithme qui a échoué, c'est l'infrastructure qui l'alimentait.
L'histoire de Sophie n'est pas unique. Selon Gartner, la mauvaise gestion des informations coûte en moyenne 12,9 millions de dollars par an aux organisations. Ce chiffre ne représente que la partie visible de l'iceberg. Au-delà de l'aspect financier direct, le manque de fiabilité des chiffres paralyse la prise de décision. On estime que les comités de direction perdent près de 40% de leur temps à débattre de la véracité des indicateurs plutôt qu'à définir des orientations stratégiques. Imaginez un CODIR où la moitié de la réunion est consacrée à savoir si les chiffres présentés sont les bons. C'est la réalité de beaucoup d'entreprises.
Harvard Business Review rapporte que les mauvaises données coûtent à l'économie américaine 3,1 trillions de dollars par an. Ce n'est pas une coquille. Trois mille milliards. Le coût de la mauvaise qualité des données dépasse de loin les investissements dans le big data lui-même. Pour mettre ce chiffre en perspective, selon Datanami, le coût moyen d'une violation de données est de 4,24 millions de dollars selon IBM. On pourrait faire tenir trois violations de données dans le coût d'une seule année de problèmes de qualité de données. Et contrairement aux violations de données qui n'arrivent pas à toutes les entreprises chaque année, les problèmes de qualité de données sont universels et permanents.
L'Intelligence Artificielle ne possède pas de conscience contextuelle. Elle suit le principe fondamental du "Garbage In, Garbage Out". Déchets en entrée, déchets en sortie. Si vos données sont polluées, l'IA ne corrigera pas le tir. Elle industrialisera l'erreur à grande échelle. C'est exactement ce qui est arrivé à Sophie. Son IA prenait des données CRM incohérentes, des historiques de support incomplets, et des données transactionnelles fragmentées, et tentait d'en faire quelque chose d'intelligent. Résultat : des prédictions pires que l'intuition humaine.
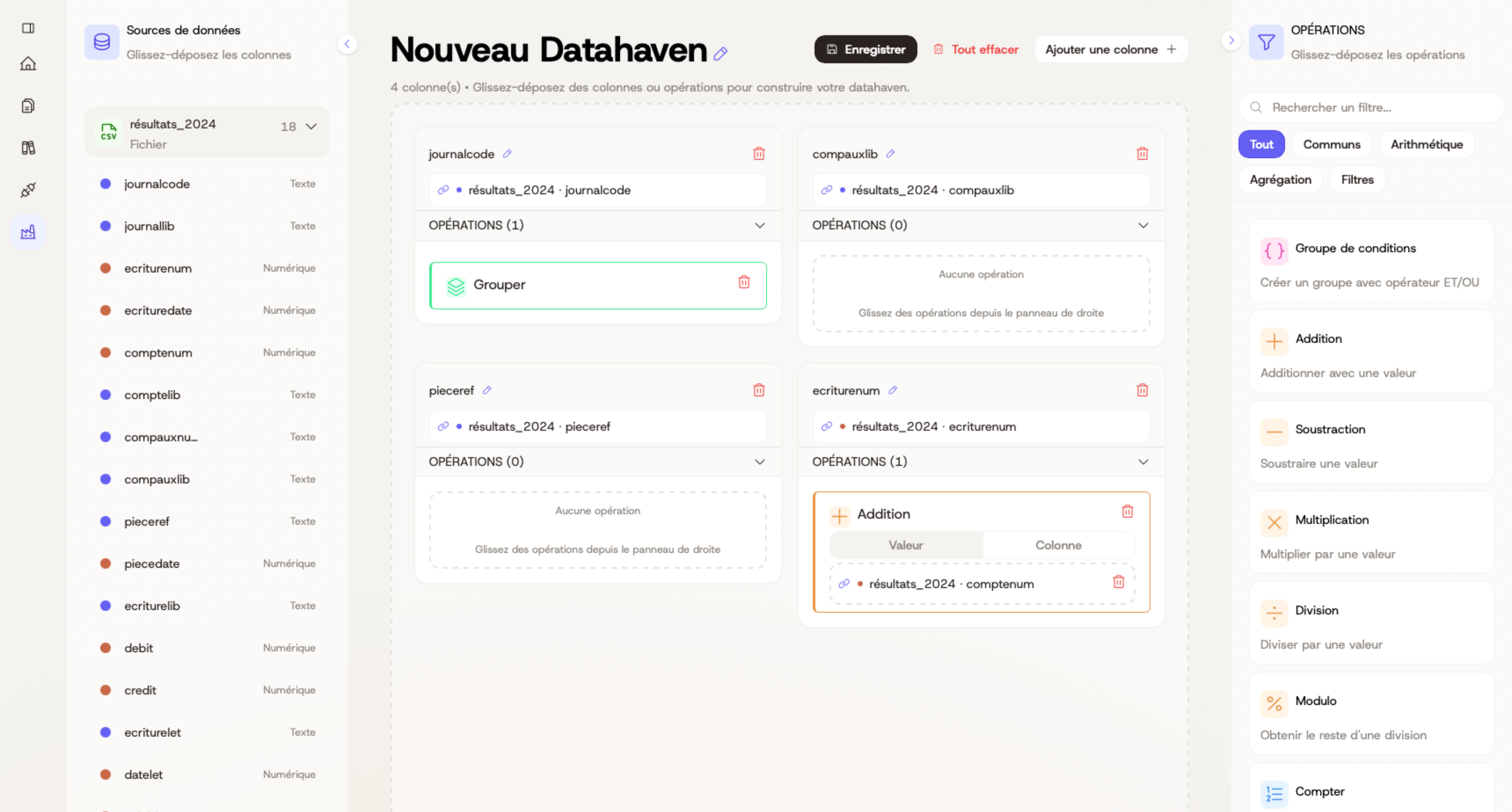
L'incohérence syntaxique est le premier obstacle. Pour un modèle de Machine Learning, "Renault" et "RENAULT" sont souvent traités comme deux entités distinctes, faussant vos segments CRM. Un client peut apparaître trois fois dans votre base avec trois variantes de son nom d'entreprise. L'IA considérera qu'il s'agit de trois clients différents. Vos prédictions de churn seront faussées. Vos segments marketing seront erronés. Vos recommandations produit seront à côté de la plaque.
Vient ensuite la fragmentation systémique. Si votre outil de facturation et votre CRM affichent des revenus différents pour le même client, l'IA est incapable de définir la vérité. Elle prendra l'un ou l'autre, ou pire, une moyenne qui ne correspond à rien de réel. Chez Sophie, le CRM indiquait un certain chiffre d'affaires par client, mais la comptabilité en montrait un autre. L'IA prédictive de churn se basait sur le CRM. Les clients classés comme "à risque" étaient en réalité parfaitement satisfaits selon les données comptables réelles.
McKinsey souligne que la préparation et le nettoyage des données représentent souvent 80% du travail d'un projet d'IA réussi. Quatre-vingts pour cent. Cela signifie que si vous budgétez un projet IA sur six mois, vous passerez près de cinq mois à nettoyer vos données avant même de commencer à entraîner un modèle. C'est ce que Sophie n'avait pas anticipé. Son budget de 100 000 euros partait du principe que les données étaient prêtes. Elles ne l'étaient pas. Une fois ce constat fait trois mois après le début du projet, il était trop tard.
Pour éviter le scénario de Sophie, il est crucial d'assainir votre patrimoine informationnel avant même de penser à l'IA. Cette méthodologie, inspirée des meilleures pratiques du Data Management Body of Knowledge, vous permet de structurer vos données pour servir vos objectifs de croissance. Quatre semaines suffisent pour poser les bases.
La première semaine consiste en l'audit et la cartographie des silos. L'objectif est de mesurer l'ampleur de la dette technique. Identifiez vos silos : Marketing, Sales, Logistique, Finance. Calculez votre taux de complétude pour chaque source. Combien de contacts CRM ont une adresse email valide ? Combien ont un numéro de téléphone ? Combien ont un historique d'achat complet ? Ne cherchez pas l'exhaustivité immédiate. Concentrez-vous sur les dix à quinze métriques critiques qui influencent réellement votre objectif final. Pour Sophie, c'était : historique d'achat, tickets support, satisfaction client, délai de réponse support, et données démographiques. Naviguer sans indicateurs fiables, c'est piloter à l'aveugle.
La deuxième semaine, passez au nettoyage intensif. Automatisez la normalisation des formats : numéros de téléphone au format international, devises standardisées, noms d'entreprise unifiés. Supprimez les doublons. L'enjeu est de créer une Single Source of Truth, une source unique de vérité. Chaque département doit s'appuyer sur le même référentiel pour que l'IA puisse apprendre sur une base cohérente et unifiée. Utilisez des outils qui détectent automatiquement les doublons même quand ils ne sont pas identiques à 100%. "Société Générale", "Societe Generale", "SG" doivent être reconnus comme la même entité.
La troisième semaine concerne la gouvernance et la correction à la source. Nettoyer les données existantes est inutile si le flux entrant reste pollué. Vous devez réparer les processus de saisie manuelle et les erreurs de tracking. L'alignement est ici humain. Comme l'explique Harvard Business Review, les travailleurs du savoir passent 50% de leur temps dans des "usines de données cachées", chassant les données, trouvant et corrigeant les erreurs, et cherchant des sources de confirmation pour les données qu'ils ne font pas confiance. La gouvernance n'est pas qu'un sujet informatique, c'est un alignement des équipes Marketing, Sales et Success sur des définitions communes. Qu'est-ce qu'un lead qualifié ? Qu'est-ce qu'un client actif ? Ces définitions doivent être les mêmes partout.
La quatrième semaine, mettez en place la Data Observability et l'automatisation. La qualité de la donnée est un cycle continu, pas un projet ponctuel. Mettez en place des outils de Data Observability pour recevoir des alertes en cas d'anomalies. Si le nombre de nouveaux contacts CRM chute brutalement, vous devez être alerté immédiatement. Si le taux de champs vides augmente soudainement, quelque chose ne va pas. Automatisez vos pipelines ETL (Extract, Transform, Load) pour garantir que votre IA travaille sur la réalité du marché actuel, et non sur des archives périmées. Les données doivent être synchronisées quotidiennement au minimum, idéalement en temps réel pour les cas d'usage critiques.
Selon Firecrawl, 70% des projets d'IA échouent. La raison principale n'est pas de mauvais algorithmes ou des modèles faibles. C'est la qualité des données. Les équipes construisent des pipelines sophistiqués et ajustent finement les paramètres, mais rien de tout cela n'a d'importance si les données sous-jacentes sont désordonnées, incomplètes ou mal structurées. Les data scientists passent 50 à 80% de leur temps de projet uniquement sur la préparation des données. Cette statistique devrait faire réfléchir tout dirigeant qui envisage un projet IA.
McKinsey rapporte que dans une récente enquête, 70% des entreprises performantes ont déclaré avoir rencontré des difficultés à intégrer les données dans les modèles d'IA, allant de problèmes de qualité des données, à la définition de processus de gouvernance des données, et à la disponibilité de données d'entraînement suffisantes. Ce n'est pas un problème de compétence technique. C'est un problème d'infrastructure de données.
Le projet de Sophie a échoué car elle a tenté d'installer un moteur de Formule 1 sur un châssis rouillé. L'IA est un amplificateur. Elle magnifie ce qui fonctionne, mais expose brutalement vos faiblesses structurelles. Si vos processus de vente sont chaotiques, l'IA amplifiera ce chaos. Si vos données client sont fragmentées, l'IA amplifiera cette fragmentation. Si vos indicateurs sont incohérents, l'IA rendra cette incohérence encore plus visible et coûteuse.
Les entreprises qui gagneront la course à l'IA sont celles qui acceptent de traiter la donnée comme un actif stratégique. Pas comme un sous-produit de leurs opérations. Pas comme quelque chose dont on s'occupe quand on a le temps. Comme un actif au même titre que leurs équipes, leurs locaux, ou leur trésorerie. Cela signifie investir dans l'infrastructure de données avant d'investir dans l'IA. Cela signifie avoir une personne ou une équipe responsable de la qualité des données. Cela signifie mettre en place des processus de gouvernance contraignants.
Avant de valider votre prochain budget d'innovation IA, posez-vous ces questions. Avez-vous une source unique de vérité pour vos données critiques ? Pouvez-vous tracer l'origine de chaque donnée ? Avez-vous des processus automatisés de détection d'anomalies ? Vos équipes utilisent-elles toutes les mêmes définitions pour les mêmes concepts ? Si la réponse à l'une de ces questions est non, vous n'êtes pas prêt pour l'IA.
Chez Kyklos, nous aidons les entreprises à devenir "IA-ready" en assainissant d'abord leur patrimoine de données. Connecter les sources, normaliser les formats, créer une source unique de vérité, mettre en place la gouvernance, automatiser la détection d'anomalies. Ce travail n'est pas sexy. Il ne fait pas de belles démos. Mais c'est ce qui fait la différence entre un projet IA à 100 000 euros qui échoue et un projet qui délivre réellement de la valeur.
Le ROI de votre IA dépend de la qualité de vos données. Pas de la sophistication de vos algorithmes. Pas du nombre de data scientists que vous embauchez. De la qualité de vos données. Point final. L'IA est un miroir, pas une baguette magique. Elle vous montrera ce que vous êtes vraiment. Assurez-vous d'être prêt à voir cette vérité.
Sources citées :


Digitalisation, e facture, pilotage : l’Italie montre le futur du cabinet français
10 Erreurs Excel qui Coûtent 50K€/an à Votre PME (et Comment les Éviter)
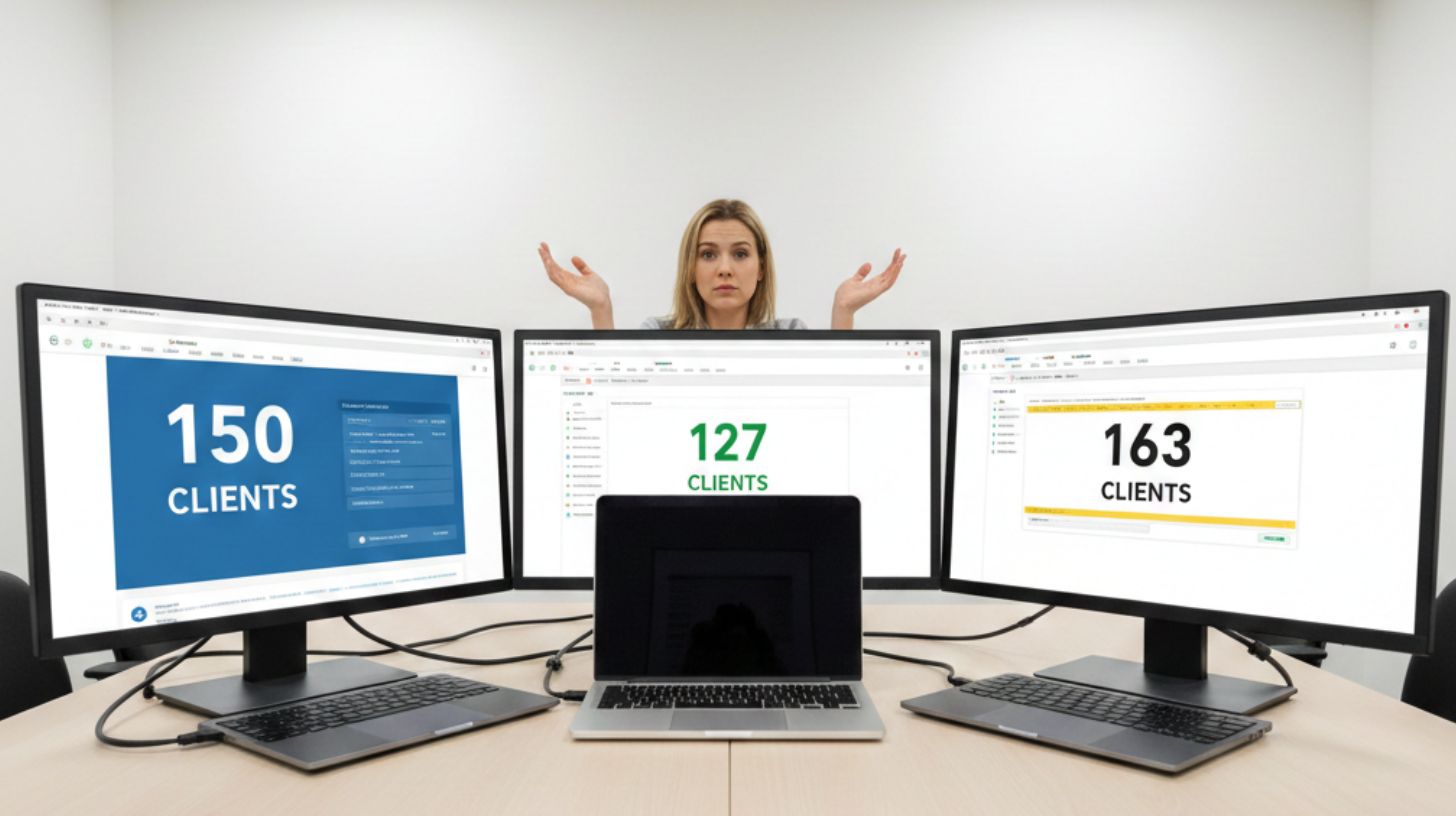
Découvrez pourquoi 87% des OKR échouent à cause de données dispersées et comment le data management transforme vos objectifs en résultats concrets. Guide complet + cas pratiques.
Découvrez comment Kyklos centralise, transforme et rend vos données immédiatement utilisables, sans équipe technique.

